
Image of the Basejump AI logo
I started thinking about building Basejump AI at the beginning of 2023 right after ChatGPT had just launched. I had been following OpenAI’s progress (and generative AI’s development as whole) and only seriously started considering launching my own company because I finally felt like the tech was ready and able to create a new kind of tool. A tool that allows users to get access to their data faster than ever before using AI.
Now data consumers can directly chat with their database …and get answers in seconds.
A Paradigm Shift
So why create Basejump AI in the first place? Well, the tool I envisioned just didn’t exist. There are so many applications and uses for generative AI and my career as a data analyst and data scientist showed me how important this could be for the data space. Even within the data space, there are quite a few applications of this technology: whether that is improving code quality by having an AI assistant embedded within your IDE, using AI to help with data management, using AI to improve and optimize data engineering workflows, or what we chose — which is using AI as a database assistant.
Of all of the various applications, how does a database assistant fundamentally change how users retrieve data?
1. Speed
Historically in order to get access to data from a database, data consumers would submit a request that would then have to be passed through several different roles. This visual is really simplified, but the workflow might look something like this:
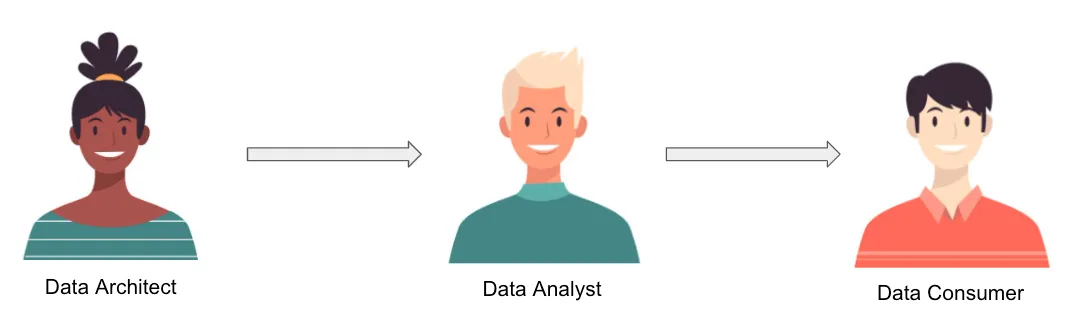
Image of the traditional workflow with explicit data modeling (ETL)
This was the ETL process where the data architect was expected to prepare clean tables for the data analyst to use and model out the relationships between them beforehand. This process was slow and led to bottlenecks between the request and when the data consumer would get access — literally taking months in many cases.
Later, dbt helped to popularize a shift to ELT. Data would be loaded first into a large data store and the analysts would then have the primary responsibility of cleaning and transforming the data. This process avoids data architects as the bottleneck, but there would still be delays between when the data analyst could provide a new dashboard or insight and the data consumer receives the data (not shown here is the rise of the role of data engineer who helps manage pipelines created).

Image of the newer workflow with ELT
The large change here was moving from ETL to ELT. This was liberating for data analysts who could quickly create and modify tables for the end consumers without needing data architects to model out all of the tables for the database in advance.
Fast-forward to today and we are seeing another shift which will further proliferate data access and increase the speed of retrieval.
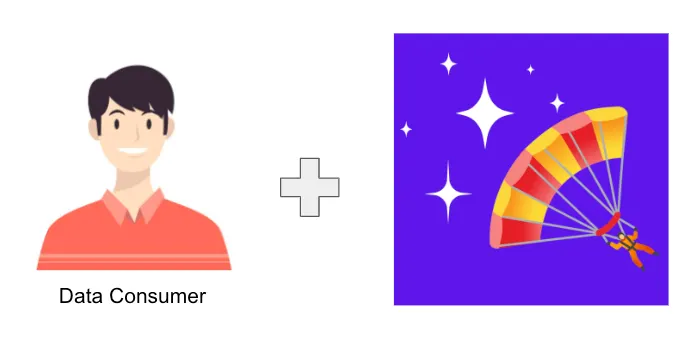
Image of the new workflow where the data consumer has access to the database using AI
Now data consumers can directly chat with their database for many questions they previously would have gone to a data analyst for. Basejump AI will perform the data transformation for the end user and get answers in seconds.
People want to be able to look at the data themselves and draw their own conclusions and confirm existing insights
2. Users want access to the data source
There have been many, many times in my career where I have heard coworkers ask, “Can I download this to a spreadsheet?” when looking at the latest dashboard. If there’s one thing I’ve learned in my career, it’s that users want direct access to the data source. People want to be able to look at the data themselves and draw their own conclusions and confirm existing insights. Dashboards are a great tool, but they don’t have to be the primary means of sharing data in an organization. That role belongs to the humble spreadsheet/dataset.
These datasets are generated by interacting with Basejump AI in chat.

Image of chatting with Basejump AI
Data can then be saved to reference later on with a user-editable title and description.
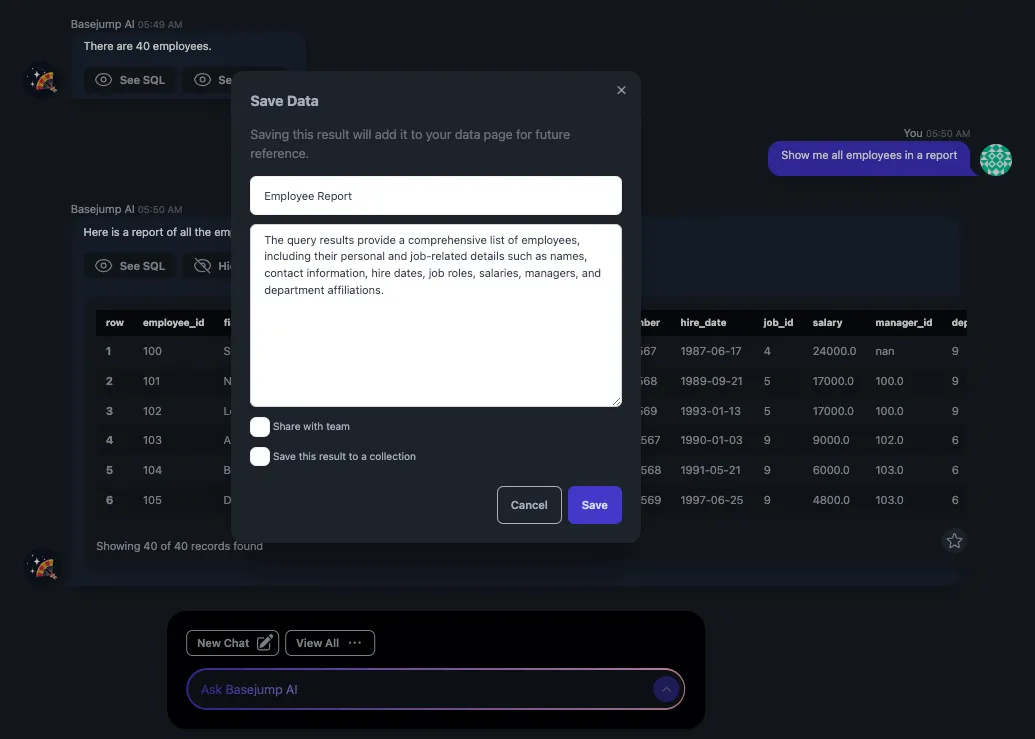
Image of saving a dataset
Over time users will build up a large list of metrics, records, and datasets that they have generated.
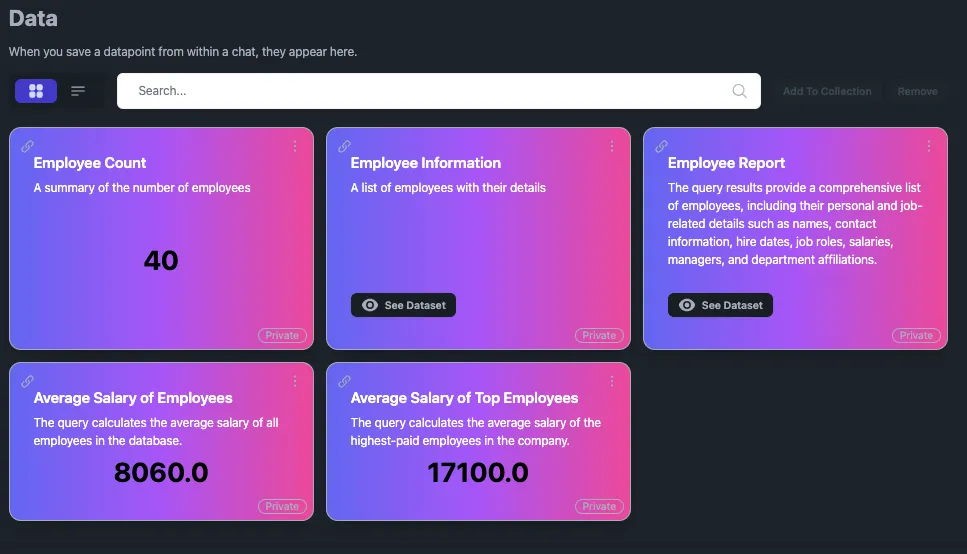
Image of the tile view of the data page
These datapoints can be set on refresh schedules, grouped into collections, and shared with users on their teams. New chats with Basejump AI can even be started from previously retrieved data.
Users will now have direct access to the source — which will further enable data democratization.
3. Users want to compare their data
Another frustrating aspect of getting access to data today is not knowing which datasets to trust. A common frustration is that one user’s metrics sometimes won’t match another’s metric when they are expected to match.
With this next generation tool, Basejump AI will take care of comparing dataset outputs for you.
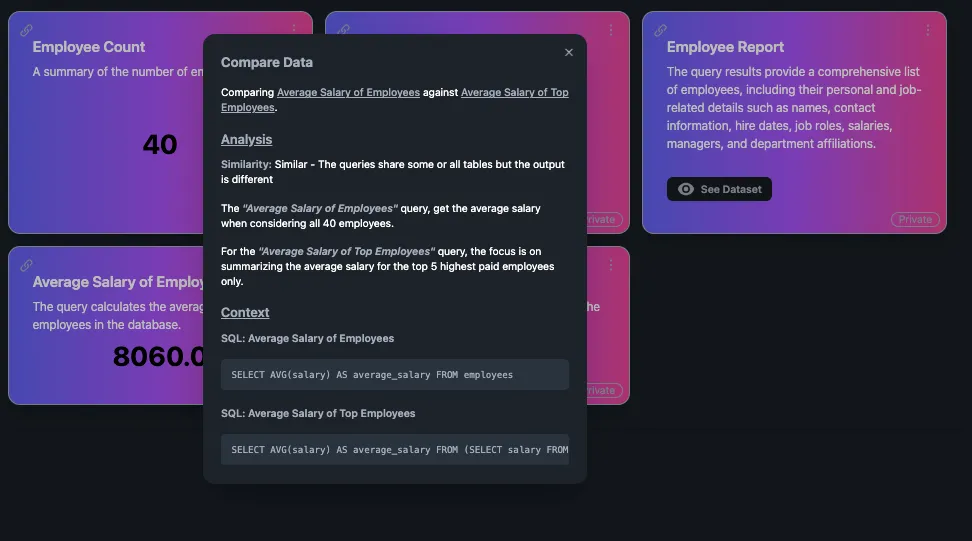
Image of comparison of two datapoints
We created a feature that allows a user to quickly compare their output with a coworkers and immediately understand why they are different since metrics can be extremely specific! There might be thousands of ways to combine tables and filter them. To make comparison simple, we classify dataset comparisons into 4 categories (in order of similarity):
- Identical: There are no differences
- Equivalent: The output and tables are the same, but queries are structured differently
- Similar: The queries share some or all tables but the output is different
- Different: The queries share no tables
Users can build trust more easily when they can see the original tables, ask questions about them, and compare the results.
Each team has a database connection provisioned to it by the company admin. This ensures data access only remains within groups that are allowed to see specific data.
How does Basejump AI handle security?
Data access + RBAC
We follow current best practices to encrypt all data including encrypting sensitive data at rest. We restrict access to all of our endpoints using either app API keys (for internal endpoints/settings), client API keys (managed by a company admin), and user access and refresh tokens. We are currently working towards our SOC II certification as well to show our dedication to ensure we’re following best practices.
We provide RBAC by organizing access into Teams. Each team has a database connection provisioned to it by the company admin. This ensures data access only remains within groups that are allowed to see specific data.
Storing the query results
We recommend our clients store the results from the AI-generated queries in their own data stores. We support the option to securely store it as well on behalf of the client.
When creating indexes for AI to use via embeddings, we only ingest table metadata and avoid embedding any of the table’s contents.
Finally, we use Azure OpenAI, which guarantees to not train on client data.
What other features does Basejump AI currently provide?
For a quick overview of features, watch our sizzle reel 🔥
Here is our current sidebar in our web app:
Screenshot of the sidebar
Some notable features not already mentioned in this article include:
- The explore page: This page lets you view tables and their descriptions and also view an ERD diagram of how the tables are related
- The API: We have an API so you can integrate Basejump into other applications
- Teams: These are admin views where permissions are handled for the various database connections via teams
- Company: The company datasources can be added here, white-label settings are available, user management, RBAC, etc…
- Subscription: Manage your subscription plan settings
There is a clear distinction between managing data that has already been created versus generating new data insights. We’re focused on the latter.
How do we compare?
Many existing AI solutions focus on data management and search. There is a clear distinction between managing data that has already been created versus generating new data insights. We’re focused on the latter. Data generation, with controls to ensure high data quality, will help empower users to discover their own precisely tailored metrics. We strongly believe direct access to the data source will empower users and enable organizations to be more data driven than ever before.
Why impose any uniform metrics across an organization when you can gain a deeper understanding of the diverse metrics at play? Many organizations invest significant effort in standardizing metrics and data points. However, with the multitude of ways to filter and combine data, enforcing any single company-wide metric is becoming increasingly impractical. Instead, users can share their unique metrics and appreciate the nuances that each brings. Business glossaries can be created both manually and automatically to define various emerging metrics. Furthermore, a common language can develop around these new definitions, fostering alignment across the organization. By leveraging AI to identify commonalities, there is substantial potential to enhance collaboration and coherence within the business.
What features are on the roadmap?
We’re only just beginning! Lots of features are planned and we will send out regular updates via our newsletter and social media platforms. Click here to follow us on our social media and sign up for the newsletter as well 👍
Thanks for reading and please let us know your thoughts! For additional information, we recently were featured on Product Hunt and answered a lot of great questions there as well:
Thanks! 🪂
— Andreas & Joel
Appendix
Quick History
The initial name for this company was DemocratizeDB. The reason for that name was because I was trying to convey how the company democratizes access to the database. Back in early 2023, I was tinkering with the WikiSQL dataset and writing some articles which according to my tests showed that using AI to write SQL queries could really work!
I then designed some mockups and built a simple website with a chat app I built using Anvil. It was basic and was a small taste of what I envisioned for the final product.
Here is one of the initial primitive designs of the chat interface:
Chatbot initial design
Here is where it is today after Joel joined:
I was working on this idea every chance I could get outside of work hours. Building a startup on the side is no joke! That’s when Joel and I met around September 2023. I used the initial PoC powered by LlamaIndex to convince Joel that this was viable — he then joined as a co-founder and CTO. We have came a long way since then and are so excited to be launching our product and share it’s awesome features with you!