
Data was once hailed as the new oil, but that narrative is evolving. With the rise of AI, compute power has now taken center stage as the critical resource businesses must secure to drive innovation and success. Sequoia doesn’t shy away from bold claims when they outline the potential impact,
“The fields that generative AI addresses — knowledge work and creative work — comprise billions of workers. [If] Generative AI can make these workers at least 10% more efficient and/or creative: they become not only faster and more efficient, but more capable than before. Therefore, Generative AI has the potential to generate trillions of dollars of economic value.”
- Sonya Huang, Pat Grady, Generative AI: A Creative New World¹
Whether this bold claim will be realized is what the markets are currently proving out. Regardless, the similarities to prior inventions and potential impact are unmistakable. Comparisons to the advent of the internet and mobile phones are abundant as people look to make comparisons to capture the allure and moment of this new technology.
So how will AI influence “knowledge work”? Data analytics in particular has experienced rapid growth in a short period, raising questions about the value that data analytics provides. This has led to an increased desire for better standards and tooling to address the need for delivering value. Recent strides have been made in improving data analytics as a profession, such as adoption of software engineering practices. Introducing a new variable like AI can seem daunting, and comes with a plethora of considerations. However, integrating AI into a company’s data strategy is crucial and neglecting it would be a missed opportunity. We argue that doing so will accelerate the realization of business value through data analytics, unlocking its full potential.
How We Got Here
The data analytics market has grown rapidly and will continue to grow — it’s expected this market will grow by a CAGR of 27.3% up through 2030².
Figure 1: North America Data Analytics Market Size, 2017–2030
Data analytics and especially data science majors were not common amongst university programs a decade ago. Prior to the advent of an increase in data science and data analytics degrees, it was much easier to transition from another analytical field to data analytics. Professionals would transition from diverse analytical backgrounds such as Physics, Math, Accounting, Economics, etc…
Nevertheless, the landscape has fundamentally changed within the last 5 years. The growth in higher education degrees reflects the interest in the field as a whole — the National Center for Education Statistics “reported a recent 968 percent jump³ in data science bachelor’s degrees awarded, from 84 in 2020 to 897 in 2022”.
Leveraging data analytics in a broad sense isn’t new — for example, accounting and finance are very analytical fields and have strict definitions and regulations when reporting metrics to the public regarding a company’s financial standing. Data analytics in the modern sense though addresses the desire to get as much information from proprietary company information as possible. This customization presents its own set of challenges and requires a different mindset from traditional software engineering. While software engineering creates a piece of code that is deterministic and possibly idempotent, data pipelines can and do change from week to week depending on the data ingestion process.
Tools of the Trade
The “shifting sand” that is data requires similar standards to software engineering, but with new tools. This is why when data mesh came out it resonated with the data community in a way reminiscent of the Agile Manifesto⁴ for software engineers. It addressed a pain point of untrustworthy and fragmented data spread across an organization. The idea of federated product ownership was enticing as well since centralized extract-transform-load (ETL) processes had become too cumbersome and sluggish to quickly serve the analytical needs of the organization.
This ushered in an emphasis on switching from ETL to ELT ,led by developer tools such as dbt⁵, where transformation of the data is the final step and is owned by the data analysts or the analytics engineers. This empowerment of the data teams, to create their own tables instead of relying on data architects to construct a data model, reduced the time data consumers had to wait to get their data.
Figure 2: The ELT Process
With this increased speed however, came a proliferation of tables derived from a few sources. The neglected aspect was considering the “final load” where the data is presented to the end user. Often ETL pipelines would go directly from the transformation to a visualization tool (such as Tableau, PowerBI, or Looker) or spreadsheet instead of back into the database as modeled data.
Figure 3: ELTL: Showing the additional steps after ELT
Possibly a more accurate acronym would be ELTL, considering there is often the final load to deliver the end results to the user. The missing piece has been the data governance step prior to this final load.
Data Governance, Data Models, and the Semantic Layer
Data delivered directly to business users without regard to data governance has caused many issues. Users would compare dashboards to each other and realize similar metrics yielded different results. Mistakes would make it into the final product since testing was not necessarily emphasized as heavily — this was unlike software engineering where unit testing is paramount. This cycle of learning that software engineering had already experienced was being repeated for the data analytics field as it matured.
In response to improve accuracy, dbt provided ways to test your workflows and debuted their semantic layer. A semantic layer defines common metrics to ensure consistency across the organization. These were important improvements to start adding more data governance to the data analytics field. Additionally, many data governance solutions with emphasis on data catalogs arose. Finally, we now have even more tools that are enriching the variety of options with a strong emphasis on software engineering principles that compete with dbt such as SQLMesh.
With those things in mind, now that we have AI, where does it fit in? AI is being used in every aspect of that final ‘load’ step — from AI in spreadsheets, visualizations, and the database. All of those final loads are important, but we believe the most important is adding AI on top of modeled data in the warehouse.
Figure 4: The AI agent then has access to many tools to present the information in the final ‘load’ step
Without this and data governance, AI initiatives will likely fail.
Semantic Layer and Data Models
There’s a balance to be struck between current AI capabilities and reliability and planning ahead the inevitable improvement of AI. According to our experience, current AI capabilities rely heavily on a well documented semantic layer. This semantic layer is built on metadata about tables in the database. These tables need to be modeled and described how they relate to one another. AI can help in discovering these relationships, but AI will be most successful when these relationships are confirmed.
Figure 5: An image of the Basejump AI ERD database explorer
The reason for the importance of all the metadata is because the AI needs context. Typical Agentic AI systems will be built using RAG (retrieval-augmented generation). RAG allows context to be retrieved and put into the prompt before sending to the AI model being used.
To improve the accuracy of these systems, agentic workflows need to be built with several checks, such as: primary key checks and join definitions. Establishing these not only allows the AI’s output to be improved, but allows tools such as SQLMesh to integrate with auditing the AI output more easily. In SQLMesh, a combination of columns that defines a row is referred to as a ‘grain’ and a join relationship are references⁶. These primitives allow an AI system to be built with guardrails and improve the accuracy beyond what RAG is able to achieve on its own.
Precision Analytics
This re-emphasis on data modeling will make some nod in agreement that we have come ‘full circle’. But this would be premature, since the differences in the process up to this point has allowed data professionals much more autonomy than before to create tables. There was a noticeable speed increase in getting data to business users. However, despite being faster, this speed is still too slow. Data teams are a bottleneck and adding new filters to a dashboard is not always the most appropriate approach for getting information to the end users. Including AI will make data querying and retrieval go from taking weeks in some cases to seconds.
This is exciting, but it’s easy to become complacent and repeat the errors of the past. Namely, allowing an even greater proliferation of data generation without concern for data governance. This is why the most successful AI data applications will come with data governance included. In our opinion, it’s not optional, but an essential characteristic to providing a reliable AI data agent.
So adding AI will increase speed, improve reliance on data modeling and governance, improve metadata and documentation practices. How else will it help? It will help to fully realize getting precisely the information you need when you need it. Some dashboards have a combination problem — there are many filters with many different options resulting in so many views you would never have time to sort through it all. AI is bringing to companies internally what Google brought to consumers: near instant access to your data along with fresh insights. This ability to get exactly what you need we are calling ‘precision analytics’. The origin of this term is borrowed from healthcare where the term ‘precision medicine’ references the ability to give someone treatment tailored specifically to them. With so many possible combinations of data and metrics, precision analytics allows an AI to get you just the right transformation of data tailored to your use case.
Data Objects
Treating an individual SQL query as its own data unit is what we refer to as a ‘data object’. Using AI a user can generate many different and unique data objects — these differ from dashboards in a few ways: they are more easily accessible and comparable. The ability to compare the data objects is built-in. Data objects have also been referred to as data products and data models, but we’re going with data objects as our working name for now to describe a SQL query that answers a user’s prompt.
Figure 6: An image of the Basejump AI data page full of data objects
A data object is currently defined as 1 of 3 things: a metric (1 row and 1 column), a record (1 row and many columns), and a dataset (many rows and many columns). Establishing data types helps to organize and share data more easily and defines how we organize our data objects.
The Advent of AI Data Analytics
We have an opportunity to address some fundamental problems in the data landscape using AI. Many tools are available already that either provide a solution that is ready to integrate with your data or something that you can build from scratch. AI data analytics solutions seem to broadly fall into two functional groups: one group of solutions queries data from sources such as your database or documents. The other group is retrieving data from reports that already exist. We want to explore these separately and then explain how they can be combined in the future.
AI Solutions to Retrieve Data From Existing Sources
These are tools that build an AI agent on top of a data catalog of analytical reports. The largest downside of retrieving data from reports that already exist as opposed to the original data source is disagreement between reports. This is why Basejump AI has focused on querying the data as a solid starting point and then building retrieval of existing reports on top of that foundation. Our prediction is tools that provide strong AI data governance and explainability will thrive.
The distinction from querying data is important here. Some companies focused only on retrieval from existing sources do not attempt to transform the data in any way, but rather present information that has already been transformed.
AI Solutions to Query Data From Original Source Data (i.e. Text-to-SQL)
Can text-to-SQL actually work? Well, if search is any indicator, progress will continue to improve. We argue that the technology is viable now for enterprise solutions to deliver accurate and relevant results. One indicator of this is the progress towards a famous Text-to-SQL benchmark called Spider⁷. The Spider benchmark is a successor of the seminal WikiSQL benchmark⁸ and addresses some of its shortcomings. The top performing model of execution with values is at 91.2% at the time of this writing. These high numbers may seem like they still have that final 9% to improve, however, AI benchmarks often have errors and an improvement beyond the current performance likely would indicate overfitting to the benchmark. For reference, the MMLU (a popular LLM benchmark) has an error rate of roughly 9%⁹.
The advent of LLMs caused the team behind the Spider benchmark to introduce a new challenge dubbed Spider 2.0¹⁰. This more challenging benchmark only has a high score currently a little over 17%. This is a multi-step workflow that can be used to test the performance of Retrieval-Augmented-Generation (RAG) workflows. This is an exciting new benchmark to help show how these systems perform in production.
Figure 7: An example of an agentic text-to-SQL workflow
So can text-to-SQL actually work? Yes, it’s already working, however, there need to be guardrails in place to ensure results are accurate enough to make a tangible impact. There are a few methods to make sure this happens and ensure that we’re being realistic with our current state of progress.
Trust, Hallucinations, and Human-in-the-Loop
Context is everything when building a successful text-to-SQL system. A common concern is whether the accuracy is sufficient to reassure the data team that their hard won trust won’t be eviscerated by an inaccurate AI system. It’s the application built around the AI that is most important; trust in the results needs to be considered from the beginning.
It’s important to be realistic with the current capabilities of these models. We have found that current systems need a foundation of good data governance and metadata in order to be successful. An AI data agent can be compared to hiring a new data analyst — if you asked the data analyst to calculate the number of leads the business has gotten in the past month, the data analyst wouldn’t know where to go without some context. Likely they would be asking many questions in order to get their bearings. Data agents are no different — with poor documentation and non-existent metadata the critics of text-to-SQL applications prove to be correct. It doesn’t work. However, for those who have well-defined schemas, up to date metadata, and a business glossary for terms internal to the business, for example, the agent can thrive.
In addition to a foundation of trust and metadata, there needs to be control provided to both the data team and business users. Whatever the form of implementation, the control provided needs to reassure both sides that they understand the source of the information and can audit it themselves. A few examples of control that benefits the data team:
- The data team needs to be notified when the AI is not confident enough to be able to answer a question, so that question would be forwarded to them.
- Ability to audit the SQL queries that the AI provided as well as the AI’s line of thinking to get to its final answer
The business users also need control over the AI by:
- Transparency into the AI thoughts in real time
- Ability to compare source tables to the final output
- Ability to work as a ‘human-in-the-loop’ and provide feedback to the AI
All of these components are only possible within an agentic architecture. Within an article from LangChain describing cognitive architectures¹¹, they provide a graphic that ranks LLM systems based on the level of capability.
Figure 8: What is a “cognitive architecture”? by Harrison Chase
Our agent at Basejump can be considered a state machine (level 5). Future agents will likely be much better at asking follow-up questions and in the case there is poor metadata, they will be able to gather that information. Successful architectures not only use their AI agents for querying and retrieval, those agents will also be able to update metadata enriched by feedback from users. This new generation of data analytics solutions will create a flywheel effect, leading to improved documentation and greater consensus on important data metrics.
We believe the most successful platforms will rely on humans in the loop to improve the AI output. Claims that AI agents are practically autonomous has resulted in underwhelming results for products such as Devin¹², but relying on humans in the loop has shown large productivity gains with tools such as Windsurf¹³ and Cursor¹⁴. It’s important that companies are realistic about current AI capabilities and build appropriate guardrails. This is why it’s likely best to refer to AI data agents as assistants to the data team as opposed to full-fledged coworkers at this point in time considering the level that humans must be in the loop to help the AI agent succeed.
Data Intelligence vs BI Platforms
The scope of what is required to launch a successful AI data application is larger than traditional BI tools. In order for AI to be successful, governance and control needs to be built in as part of the solution and not an afterthought. That is why we prefer to use the term, data intelligence platform¹⁵ or AI Data Analytics Platform. Some key aspects of a data intelligence platform that go beyond an emphasis on visualization like traditional BI platforms includes:
- Natural language access (i.e. a ‘cognitive layer’)
- Semantic Cataloguing and Discovery
- Automated Management and Optimization
- Enhanced Governance and Privacy
At Basejump AI, we take a data source agnostic approach, which we believe is important to allow engineers to do what they do best — pick the appropriate technologies to build robust experiences for their users. Any source that can be queried using SQL can be used, which opens up a world of possibilities as there are ever more tools implementing SQL interfaces to query data. Not only do we provide an API to build your own UI on top of our solution, we provide a beautiful interface already prepared to start providing insights to users.
Who Benefits?
So who benefits from a solution like this? The main beneficiaries are:
- The data team
- The business users (i.e. data consumers)
How Data Agents Help Data Teams
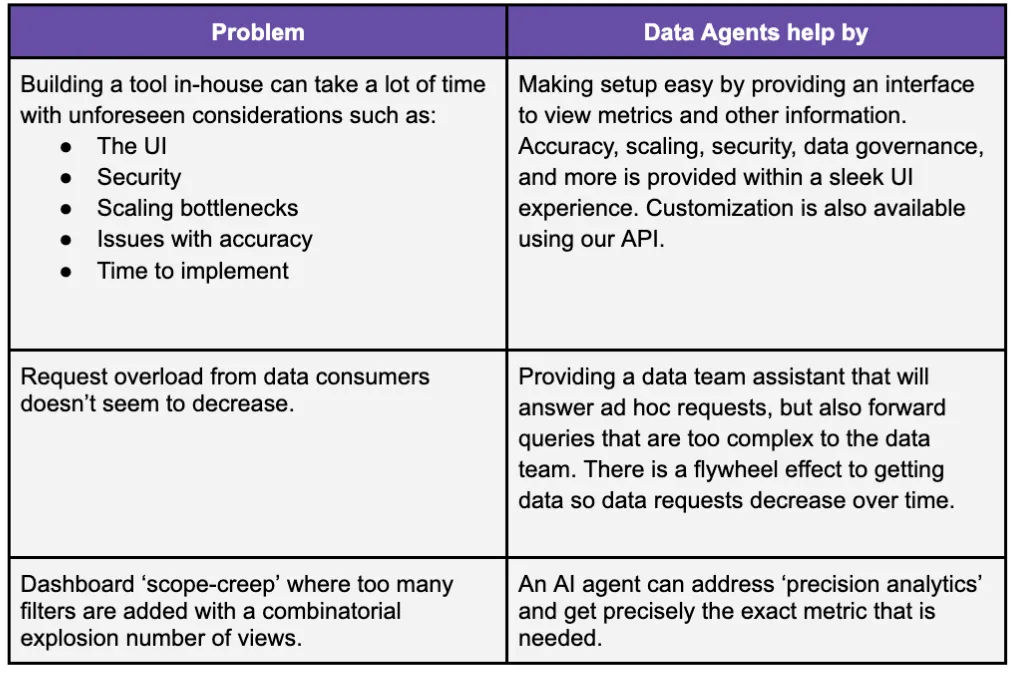
How Data Agents Help Business Users
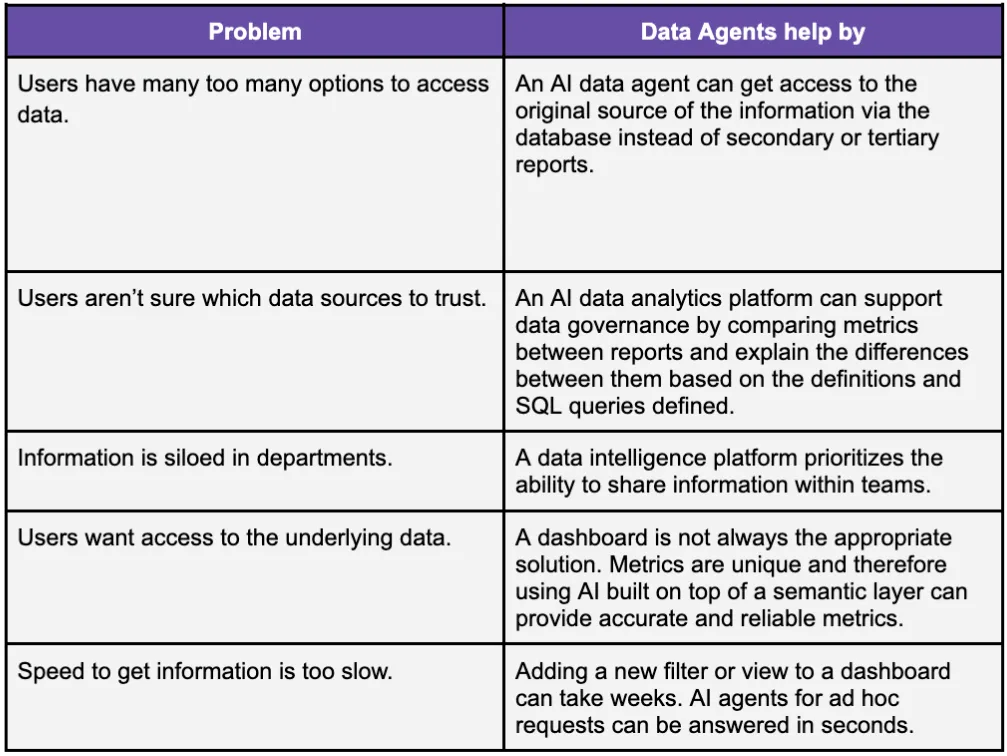
Basejump AI is an AI data analytics platform built to address these problems with data governance and sharing of metrics is built in.
The Data Agent Moment
Many companies are advertising ‘your own AI data analyst’ or ‘a personal AI data scientist’. However, the future will be by integrating all of these data roles into a data agent. This data agent will be able to eventually cover all aspects of the data maturity lifecycle. This includes:
- Ad Hoc and Reactive
- Descriptive Reporting (“What happened”)
- Diagnostic Reporting (“Why did it happen?”)
- Predictive Analytics (“What will happen?”)
- Prescriptive Analytics (“How can we make it happen?”)
Most solutions are covering a specific aspect of the data maturity lifecycle. However, our goal is to eventually encapsulate all areas to truly deliver value to the business. We are excited to help shape this vision as we move forward into the inevitable transition of AI-enabled data analytics!
About Us
Basejump AI is an AI Data Analytics platform designed to empower organizations to effortlessly interact with their data. By leveraging AI-powered data agents, Basejump AI enables teams to quickly and accurately answer data-driven questions. Our core offering is a data agent that acts as a trusted, vital member of the data team, providing on-demand insights to address ad hoc queries across the organization.
If you’re interested in an AI analytics solution for your business, you can:
- Try our product for free: https://basejump.ai/
- Book a demo: https://basejump.ai/demo.
Author
Andreas Martinson, Co-founder and CEO of Basejump AI
LinkedIn: https://www.linkedin.com/in/andreasmartinson/
References
- Sonya Huang, Pat Grady, Generative AI: A Creative New World (2022), Sequoia Capital
- Data Analytics Market Size, Share Analysis… (2024), Fortune Business Insights
- Lauren Coffey, Data Science Major Takes Off (2024), Inside Higher Ed
- Kent Beck, James Grenning, Robert C. Martin et. al, Manifesto for Agile Software (2001)
- What is ELT (Extract, Load, Transform)? (2024), dbt
- SQLMesh Docs, SQLMesh
- Spider 1.0: Yale Semantic Parsing and Text-to-SQL Challenge, Yale University
- WikiSQL, Github
- Aryo Pradipta Gema, et. al, Are we Done with MMLU? (2024), Arxiv
- Fangyu Lei, Jixuan Chen, Yuxiao Ye, et. al, Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-SQL Workflows, Yale University
- Harrison Chase, What is a “cognitive architecture”? (2024), LangChain
- Devin
- Windsurf
- Cursor
- Michael Armbrust, Adam Conway, et. al., Data Intelligence Platforms (2023), Databricks